
Building Production-Grade Agentic RAG Systems: A Deep Dive
Introduction
Retrieval-Augmented Generation (RAG) has become the de facto standard for grounding large language models with domain-specific knowledge. The basic RAG pipeline—embed documents, retrieve top-k chunks for a query, pass to LLM—works well for straightforward questions with clear answers in a single document. But real-world systems face more complex challenges: users ask multi-part questions, queries require information from multiple sources, and retrieval often returns partially relevant documents that leave critical gaps.
In my previous article on LangChain and Streamlit RAG, I explored building a basic RAG chatbot that could answer questions from indexed documents. While that system worked for simple queries, it quickly revealed its limitations when faced with complex questions requiring multiple retrieval passes or information synthesis from multiple sources.
Agentic RAG systems use LLMs to orchestrate the retrieval and generation process, making decisions about when to retrieve, when to iterate, and how to decompose complex queries. Unlike traditional “naive” RAG, agentic systems can reason about what information is missing, rewrite queries based on gaps in retrieved context, and synthesize answers from multiple retrieval passes.
In this article, we’ll explore how to build a more powerful agentic RAG system using LangGraph for workflow orchestration, examining real implementation patterns and performance trade-offs. We’ll cover the architecture and how it improves context precision and context recall on complex multi-hop queries, the evidence-gap critic that enables iterative refinement, and the map-reduce pattern that makes query decomposition practical. This makes the system better adapt to different use cases from simple to complex queries.
This article is based on the rag_agent project, an open-source codebase with unit and integration test coverage and an evaluation framework. This is not a trivial tutorial example, but a real system that demonstrates the complexity and rigor required for building a realistic RAG systems. When you compare the size of the code for the agent itself to the supporting testing, evaluation, and validation code, it becomes clear where the real work lies in a practical production-ready solution. This is even more clear when you realize that it still does not include any of the deployment pipelines, production automation, and other operational concerns of running a multi-user system in production.
The Limitations of Naive RAG
Naive RAG based on a single retrieval pass with top-k chunks will not always yield sufficient context to answer a question. This works well for simple, single-hop queries like “What is RAG?” but can break down on complex questions that require:
- Information from multiple documents
- Multi-step reasoning
- Comparison or evaluation of different options
- Synthesis of related concepts
Consider a query like “Compare the advantages and disadvantages of RAG versus fine-tuning for domain-specific knowledge.” A naive RAG system would:
- Retrieve the top-k most relevant chunks for the original query
- Pass those chunks (along with the query) to the LLM
- Generate an answer
A multi-step retrieval also allows going deeper than the information retrieved by the simple solution by incorporating mechanisms like reflection and subqueries.
Context Precision vs. Recall Trade-off
Naive RAG faces a fundamental trade-off between precision and recall. If you retrieve fewer documents (small k), you get higher precision but lower recall meaning you might miss crucial information. If you retrieve more documents (large k), you improve recall but reduce precision and include irrelevant context that can confuse the LLM.
The Multi-Hop Query Problem
Multi-hop queries require multiple steps of reasoning and information from different sources. For example: “What are the main criticisms of RAG systems, and how do agentic approaches address them?”
A naive RAG system would retrieve chunks mentioning “criticisms of RAG” and chunks mentioning “agentic approaches,” but it cannot follow up iteratively to dentify which criticisms are most relevant, determine which agentic techniques address which criticisms and then synthesize data from multiple queries into a final answer.
The Evidence Gap Problem
Even when retrieval returns relevant documents, there may be an gap in supporting context where the documents touch on the topic but miss specific details needed to answer the question completely. For example, a document might explain “RAG uses retrieval” but not explain how the retrieval process works or why it improves over fine-tuning.
Naive RAG has no mechanism to detect these gaps or iteratively refine retrieval. It’s a single-shot system: retrieve once, generate once, done.
Why We Need Agents
These limitations point to a fundamental architectural change: instead of treating retrieval as a one-time operation, we need systems that can:
- Make decisions: Decide whether retrieval is needed at all (some queries can be answered from training data)
- Evaluate results: Analyze whether retrieved context is sufficient
- Iterate intelligently: Rewrite queries based on gaps in retrieved information
- Decompose complexity: Break complex queries into answerable subquestions
- Synthesize answers: Integrate information from multiple retrieval passes
This is where agentic RAG comes in by using LLMs to orchestrate the retrieval and generation process, making the system more adaptive.
Why LangGraph?
LangGraph provides a powerful framework for building agentic RAG systems by modeling workflows as state machines with nodes and conditional edges. LangGraph allows you to build complex, adaptive workflows where the path through the graph depends on the current state.
LangGraph is designed specifically for building agentic systems, and in my experience it strikes the right balance: it’s declarative (you describe the graph structure), type-safe (with TypedDict state), and Pythonic (fits naturally with LangChain’s message and tool abstractions).
State Machine Architecture
The core of a LangGraph workflow is state, in our case a TypedDict that accumulates information as the graph executes. In our agentic RAG system, we use InstrumentedMessagesState:
class InstrumentedMessagesState(TypedDict, total=False):
# Messages with reducer for accumulation
messages: Annotated[list[BaseMessage], add_messages]
# Execution tracking
__execution_trace__: Optional[ExecutionTrace]
__rewrite_attempts__: int
__retrieval_attempts__: int
# Query decomposition
__query_plan__: Optional[Dict[str, Any]]
__subquery_results__: Optional[Dict[str, Any]]
# Evidence-gap analysis
__evidence_gap_analysis__: Optional[Dict[str, Any]]
# Evidence store for citation tracking
evidence_by_id: Optional[Dict[str, Dict[str, Any]]]
evidence_sets: Optional[Dict[str, List[str]]]
used_citations: Optional[List[str]]
The Annotated[list[BaseMessage], add_messages] syntax tells LangGraph to use a custom reducer that accumulates messages across nodes, rather than replacing the list. This is crucial for maintaining conversation history.
Node-Based Workflow
In LangGraph, each node is a function that takes state and returns state updates (a dictionary with keys to update). Nodes can:
- Read from state (e.g., the current question, retrieved context)
- Perform operations (e.g., call an LLM, invoke a tool)
- Update state (e.g., store analysis results, increment counters), if they are not a conditional node.
Here’s the basic structure of our graph:
def build_rag_graph(
retriever_tool: BaseTool,
model: BaseLanguageModel,
enable_query_decomposition: bool = True,
max_retrieval_attempts: int = 2,
**kwargs
):
workflow = StateGraph(InstrumentedMessagesState)
# Add nodes
workflow.add_node("generate_query_or_respond", ...)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node("evidence_gap_analysis", ...)
workflow.add_node("rewrite_question", ...)
workflow.add_node("generate_answer", ...)
if enable_query_decomposition:
workflow.add_node("planner", ...)
workflow.add_node("subquery_map", ...)
workflow.add_node("synthesis", ...)
# Add edges (conditional and unconditional)
workflow.add_edge(START, "planner" if enable_query_decomposition else "generate_query_or_respond")
workflow.add_conditional_edges("generate_query_or_respond", ...)
workflow.add_edge("retrieve", "evidence_gap_analysis")
workflow.add_conditional_edges("evidence_gap_analysis", ...)
return workflow.compile()
Conditional Routing
Conditional edges allow the graph to make routing decisions based on state. For example, after evidence gap analysis, we route to either “generateanswer” (if evidence is sufficient) or “rewritequestion” (if more evidence is needed):
def gap_analysis_router(state: State) -> str:
analysis = state.get("__evidence_gap_analysis__", {})
should_generate = analysis.get("should_generate", True)
retrieval_attempts = state.get("__retrieval_attempts__", 0)
max_attempts = 2
if should_generate or retrieval_attempts >= max_attempts:
return "generate_answer"
else:
return "rewrite_question"
This routing function is called by LangGraph after the evidence_gap_analysis node executes, allowing the workflow to adapt based on the analysis results.
Architecture Diagram
The complete architecture (with all features enabled) looks like this:
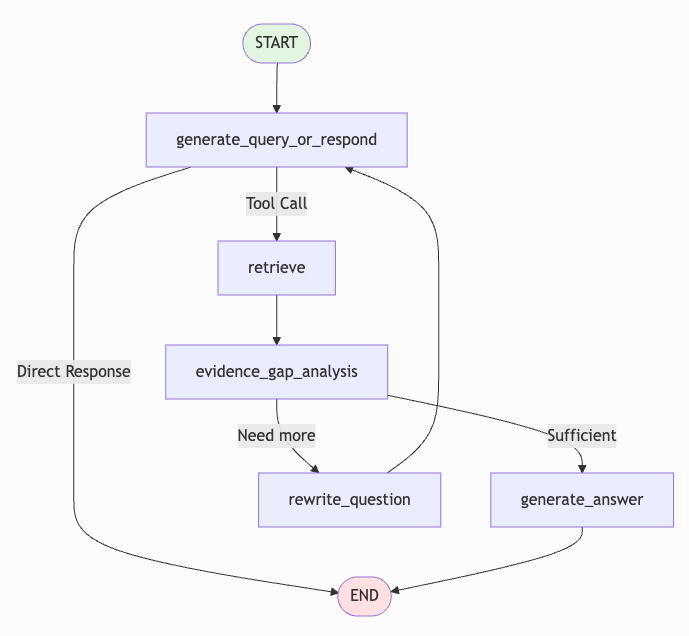
START → planner (if decomposition enabled)
↓
├─ needs_decomposition → subquery_map → synthesis → END
└─ no_decomposition → generate_query_or_respond
↓
├─ Tool Call? → retrieve → evidence_gap_analysis
│ ↓
│ ├─ Sufficient? → generate_answer → END
│ └─ Need more? → rewrite_question → (loop back)
└─ Direct Response → END
This diagram shows how the graph can take different paths based on query complexity and retrieval quality, enabling adaptive behavior that naive RAG cannot achieve.
Core Workflow: Decision → Retrieve → Evaluate → Refine
The core workflow of our agentic RAG system follows a pattern: decide whether to retrieve, retrieve if needed, evaluate the results, and refine if necessary. Each step is implemented as a graph node that reads from and updates the shared state.
Intelligent Retrieval Decision
Not every query requires retrieval. Some questions can be answered from the LLM’s training data (e.g., “What is Python?"). The generate_query_or_respond node makes this decision by binding the retriever tool to the model and letting the LLM decide whether to call it.
def create_generate_query_or_respond_node(
model: BaseLanguageModel,
retriever_tool: BaseTool,
enable_hyde: bool = True,
**kwargs
):
model_with_tools = model.bind_tools([retriever_tool])
def generate_query_or_respond(state: State) -> dict:
# Check if this is the first pass
has_retrieved_before = any(
isinstance(msg, ToolMessage) for msg in state["messages"]
)
if not has_retrieved_before:
# First pass: force retrieval
# (This ensures we always retrieve at least once)
query = _get_latest_question(state["messages"])
forced_tool_call = ToolCall(
name=retriever_tool.name,
args={"query": query},
id="forced_retrieval"
)
return {"messages": [AIMessage(content="", tool_calls=[forced_tool_call])]}
else:
# Not first pass: let LLM decide
response = model_with_tools.invoke(state["messages"])
return {"messages": [response]}
return generate_query_or_respond
The key insight here is the “first-pass guarantee": we always force retrieval on the first pass, regardless of what the LLM decides. This prevents the system from skipping retrieval when it might be needed, while still allowing the LLM to skip retrieval on subsequent passes (after query rewriting) if it determines retrieval isn’t helping.
On later passes (after query rewriting), the LLM can choose to respond directly if it believes the question cannot be answered from the knowledge base. This prevents infinite loops when retrieval consistently fails.
Evidence-Gap Critic: Iterative Refinement
After retrieval, the system analyzes whether the retrieved context is sufficient to answer the question. This is the job of the evidence_gap_analysis node, which uses structured output to identify gaps in the evidence.
The node uses a Pydantic model to structure the analysis:
class EvidenceGapAnalysis(BaseModel):
is_sufficient: bool
missing_points: list[str]
unsupported_claims: list[str]
next_retrieval_tasks: list[RetrievalTask]
confidence: str # "high", "medium", "low"
should_generate: bool # Routing decision
The analysis node is always enabled and runs after every retrieval. Here’s the core implementation:
def create_evidence_gap_analysis_node(
model: BaseLanguageModel,
max_retrieval_attempts: int = 2
):
critic = model.with_structured_output(EvidenceGapAnalysis)
def evidence_gap_analysis(state: State) -> dict:
messages = state["messages"]
question = _get_latest_question(messages)
# Get retrieved context (last ToolMessage)
context = ""
for msg in reversed(messages):
if isinstance(msg, ToolMessage):
context = msg.content
break
# Analyze gaps
prompt = f"""You are an evidence gap critic analyzing whether retrieved
context is sufficient to answer a question.
Question: {question}
Retrieved Context:
{context}
Analyze:
- Is the context sufficient to answer the question completely?
- What points are missing or unclear?
- Are there unsupported claims that need more evidence?
- What specific information should be retrieved to fill gaps?"""
analysis = critic.invoke([{"role": "user", "content": prompt}])
retrieval_attempts = state.get("__retrieval_attempts__", 0)
should_generate = (
analysis.is_sufficient or
retrieval_attempts >= max_retrieval_attempts
)
return {
"__evidence_gap_analysis__": {
"is_sufficient": analysis.is_sufficient,
"missing_points": analysis.missing_points,
"unsupported_claims": analysis.unsupported_claims,
"next_retrieval_tasks": [
{"query": task.query, "focus": task.focus}
for task in analysis.next_retrieval_tasks
],
"should_generate": should_generate
},
"__retrieval_attempts__": (
0 if should_generate else retrieval_attempts + 1
)
}
return evidence_gap_analysis
The analysis identifies:
- Missing points: Information needed to answer the question that isn’t in the retrieved context
- Unsupported claims: Claims in the context that lack supporting evidence
- Next retrieval tasks: Targeted queries to fill specific gaps
The routing decision (should_generate) determines whether to proceed to answer generation (if evidence is sufficient or max attempts reached) or to rewrite the query for another retrieval attempt.
This iterative refinement process typically requires 2-4 retrieval passes for complex queries, but the system is bounded by max_retrieval_attempts to prevent infinite loops.
Query Rewriting with Context
When the evidence gap analysis determines that more information is needed, the rewrite_question node reformulates the query to target the missing information. The key innovation here is using the gap analysis results to guide the rewriting:
def create_rewrite_question_node(model: BaseLanguageModel):
def rewrite_question(state: State) -> dict:
original_question = _get_latest_question(state["messages"])
gap_analysis = state.get("__evidence_gap_analysis__", {})
# Use gap analysis for targeted rewriting
if gap_analysis.get("next_retrieval_tasks"):
retrieval_tasks = gap_analysis["next_retrieval_tasks"]
missing_points = gap_analysis.get("missing_points", [])
# Use suggested query from gap analysis
task = retrieval_tasks[0]
rewritten_query = task.get("query", original_question)
else:
# Fallback: general rewriting
prompt = f"""Rewrite this question to improve retrieval results.
Original question: {original_question}
Create a more specific, focused query that will retrieve relevant information."""
response = model.invoke([{"role": "user", "content": prompt}])
rewritten_query = response.content
# Update messages with rewritten question
rewritten_message = HumanMessage(content=rewritten_query)
return {"messages": [rewritten_message]}
return rewrite_question
The rewritten query loops back to generate_query_or_respond, creating an iterative refinement cycle that continues until either:
- The evidence is sufficient (as determined by gap analysis)
- The maximum retrieval attempts are reached (preventing infinite loops)
This targeted rewriting, guided by gap analysis, is more effective than blind query rewriting because it focuses on specific missing information rather than guessing what might help.
Query Decomposition and Map-Reduce
For complex queries that require information from multiple sources or multi-step reasoning, a single retrieval pass is insufficient. The solution is query decomposition: breaking complex questions into focused subquestions that can be answered independently, then synthesizing the results.
The Multi-Hop Problem
Consider a query like “Compare the advantages and disadvantages of RAG versus fine-tuning for domain-specific knowledge.” This query requires:
- Information about RAG advantages
- Information about RAG disadvantages
- Information about fine-tuning advantages
- Information about fine-tuning disadvantages
- Comparison and synthesis
A single retrieval pass for “Compare RAG and fine-tuning” will return chunks that mention both concepts, but these chunks are often introductory or high-level. They rarely contain the specific advantages and disadvantages needed for a meaningful comparison.
Even with query rewriting, the system struggles because it’s trying to retrieve all the information at once. The solution is to decompose the query into focused subquestions:
- “What are the advantages of RAG for domain-specific knowledge?”
- “What are the disadvantages of RAG for domain-specific knowledge?”
- “What are the advantages of fine-tuning for domain-specific knowledge?”
- “What are the disadvantages of fine-tuning for domain-specific knowledge?”
Each subquestion can be answered with focused retrieval, and the results can be synthesized into a coherent comparison.
Planner Node: Query Analysis
The planner node analyzes the question and determines if it needs decomposition. It uses structured output to create a query plan:
class QueryPlan(BaseModel):
needs_decomposition: bool
subquestions: list[SubQuestion]
global_constraints: list[str]
stop_condition: str
reasoning: str
class SubQuestion(BaseModel):
id: str # e.g., "sq1", "sq2"
question: str
must_have_constraints: list[str]
expected_answer_type: str # "factual", "comparison", "list", etc.
priority: str # "high", "normal", "low"
The planner implementation:
def create_planner_node(model: BaseLanguageModel):
planner = model.with_structured_output(QueryPlan)
def plan_query(state: State) -> dict:
question = _get_latest_question(state["messages"])
prompt = f"""You are a query planner that analyzes questions and determines
if they need to be decomposed into subquestions.
Complex queries that typically need decomposition:
- Compare/contrast questions (e.g., "Compare X and Y")
- Multi-hop questions requiring multiple steps of reasoning
- Questions with multiple parts (e.g., "What are X, Y, and Z?")
- Evaluation questions (e.g., "Evaluate the pros and cons of X")
Simple queries that DON'T need decomposition:
- Single factual questions (e.g., "What is X?")
- Direct lookup questions (e.g., "When did X happen?")
Question: {question}
Analyze this question and create a query plan."""
plan = planner.invoke([{"role": "user", "content": prompt}])
return {
"__query_plan__": {
"needs_decomposition": plan.needs_decomposition,
"subquestions": [
{
"id": sq.id,
"question": sq.question,
"must_have_constraints": sq.must_have_constraints,
"expected_answer_type": sq.expected_answer_type,
"priority": sq.priority
}
for sq in plan.subquestions
],
"global_constraints": plan.global_constraints,
"reasoning": plan.reasoning
}
}
return plan_query
The planner routes to either subquery_map (if decomposition is needed) or generate_query_or_respond (for simple queries).
Map Phase: Parallel Subquery Retrieval
The subquery_map node implements the “map” phase of the map-reduce pattern: it retrieves context for each subquestion separately, ensuring each subquestion gets focused retrieval:
def create_subquery_map_node(retriever_tool: BaseTool):
def map_subqueries(state: State) -> dict:
query_plan = state.get("__query_plan__", {})
subquestions = query_plan.get("subquestions", [])
subquery_results = {}
all_contexts = []
# Process each subquestion
for sq in subquestions:
sq_id = sq["id"]
sq_question = sq["question"]
# Invoke retriever for this subquestion
context = retriever_tool.invoke(sq_question)
# Tag the context with subquestion info
tagged_context = f"=== Evidence for: {sq_question} ===\n{context}"
subquery_results[sq_id] = {
"question": sq_question,
"context": context,
"priority": sq.get("priority", "normal")
}
all_contexts.append(tagged_context)
# Combine all contexts
combined_context = "\n\n---\n\n".join(all_contexts)
return {
"messages": [ToolMessage(content=combined_context, tool_call_id="subquery_map")],
"__subquery_results__": subquery_results
}
return map_subqueries
By retrieving context for each subquestion separately, we avoid the context ordering issues that occur when using a single retrieval with query rewriting. Each subquestion gets its own focused retrieval, improving precision.
Reduce Phase: Synthesis
The synthesis node implements the “reduce” phase: it integrates evidence from all subquestions into a coherent final answer:
def create_synthesis_node(model: BaseLanguageModel):
def synthesize_answer(state: State) -> dict:
question = _get_latest_question(state["messages"])
query_plan = state.get("__query_plan__", {})
subquestions = query_plan.get("subquestions", [])
# Get combined context from subquery_map
context = ""
for msg in reversed(state["messages"]):
if isinstance(msg, ToolMessage):
context = msg.content
break
prompt = f"""You are synthesizing answers from multiple subquestions.
Original Question: {question}
Subquestions:
{chr(10).join(f"- {sq['question']}" for sq in subquestions)}
Retrieved Context (tagged by subquestion):
{context}
Synthesize a coherent answer that integrates evidence from all subquestions.
Use citations [Source N] for all factual claims."""
response = model.invoke([{"role": "user", "content": prompt}])
return {"messages": [AIMessage(content=response.content)]}
return synthesize_answer
The synthesis node produces a final answer that integrates information from all subquestions, maintaining citation tracking across the entire process.
Advanced Retrieval Techniques
Beyond the core workflow, the system supports several advanced retrieval techniques that improve quality on specific query types.
HyDE Query Expansion
HyDE (Hypothetical Document Embeddings) generates a hypothetical document that answers the query, then uses that document’s embedding for retrieval instead of the original query. This helps with ambiguous queries and conceptual questions where the query terms don’t match the document vocabulary.
The HyDE implementation:
class HyDEExpander:
def __init__(self, llm: BaseLanguageModel, enable_caching: bool = True):
self.llm = llm
self._cache = {} if enable_caching else None
def expand(self, query: str) -> str:
# Check cache
if self._cache and query in self._cache:
return self._cache[query]
# Generate hypothetical document
prompt = f"""Write a clear, informative paragraph (100-150 words) that
directly answers the user's question. Focus on the most important facts and
key concepts.
Question: {query}
Answer:"""
response = self.llm.invoke(prompt)
hyde_passage = response.content
# Cache result
if self._cache is not None:
self._cache[query] = hyde_passage
return hyde_passage
HyDE is optionally enabled and can use smart routing to decide when to use it (factual queries typically don’t benefit, while reasoning queries may).
Hybrid Retrieval
The system supports hybrid retrieval combining BM25 (keyword search), dense vector search, and optionally knowledge graph-based retrieval using Reciprocal Rank Fusion (RRF). This improves recall by covering exact keyword matches, semantic similarity, and entity relationships:
# Simplified hybrid retrieval (BM25 + Dense + optional KG)
class HybridRetriever:
def __init__(
self,
dense_retriever: BaseRetriever,
bm25_retriever: BM25Retriever,
kg_retriever: BaseRetriever | None = None,
weights: list[float] | None = None, # [BM25, Dense, KG]
):
self.dense_retriever = dense_retriever
self.bm25_retriever = bm25_retriever
self.kg_retriever = kg_retriever
# Default weights: [BM25, Dense, KG] = [0.4, 0.4, 0.2]
self.weights = weights or [0.4, 0.4, 0.2] if kg_retriever else [0.5, 0.5]
def invoke(self, query: str) -> list[Document]:
all_results = []
# 1. BM25 retrieval (keyword matching)
bm25_results = self.bm25_retriever.invoke(query)
for doc in bm25_results:
doc.metadata["retrieval_method"] = "bm25"
all_results.append(doc)
# 2. Dense retrieval (semantic similarity)
dense_results = self.dense_retriever.invoke(query)
for doc in dense_results:
doc.metadata["retrieval_method"] = "dense_vector"
all_results.append(doc)
# 3. Optional: Knowledge graph retrieval (entity-based)
if self.kg_retriever:
kg_results = self.kg_retriever.invoke(query)
for doc in kg_results:
doc.metadata["retrieval_method"] = "knowledge_graph"
all_results.append(doc)
# 4. Merge using Reciprocal Rank Fusion
weights_dict = {
"bm25": self.weights[0],
"dense_vector": self.weights[1]
}
if self.kg_retriever and len(self.weights) > 2:
weights_dict["knowledge_graph"] = self.weights[2]
merged_results = reciprocal_rank_fusion(
all_results,
k=60, # RRF constant
weights=weights_dict
)
return merged_results
Hybrid retrieval is enabled by default and provides better coverage than dense-only retrieval, especially for queries with specific technical terms. The 3-way hybrid (BM25 + Dense + KG) is optional and adds entity-based retrieval for queries that benefit from knowledge graph traversal. The system uses configurable weights (default [0.4, 0.4, 0.2] for 3-way hybrid) to balance the contributions of each retrieval method.
Knowledge Graph Construction and Retrieval
The system includes an optional domain-agnostic knowledge graph that enhances retrieval by capturing entity relationships and enabling multi-hop reasoning. Unlike domain-specific knowledge graphs that require custom schemas, this implementation uses universal linguistic patterns to extract entities and relations from any text corpus, making it applicable across diverse domains without manual configuration.
Entity Extraction
The knowledge graph construction uses a two-stage entity extraction process:
- Named Entity Recognition (NER): Uses spaCy’s pre-trained models to identify standard entity types (PERSON, ORG, GPE, LOC, etc.) from 15 categories
- Noun Phrase Extraction: Captures domain-specific concepts missed by NER, filtering out pronouns and overly long phrases
Each extracted entity receives a confidence score computed from universal linguistic signals:
- Length: Multi-word entities (2-4 words) score higher as they’re more specific
- Position: Entities appearing early in text score higher (likely topic entities)
- Capitalization: Title case and acronyms indicate named entities
- Syntactic Role: Entities in important dependency roles (subject, object) score higher
Entities are normalized (lowercased, whitespace normalized, organizational suffixes removed) and deduplicated before being added to the graph.
Relation Extraction
Relations are extracted using four universal linguistic patterns that work across domains:
- SVO (Subject-Verb-Object) Relations: Extracts relations from transitive verbs (e.g., “Apple acquired Beats” →
(Apple, acquired, Beats)) - Copula Relations: Captures “is-a” relationships (e.g., “Python is a language” →
(Python, is_a, language)) - Attribute/Possession Relations: Extracts “has” relationships (e.g., “Apple has employees” →
(Apple, has, employees)) - Prepositional Relations: Captures spatial, temporal, and associative relations (e.g., “Office in Seattle” →
(Office, located_in, Seattle))
Each relation pattern has a confidence score (copula: 0.90, SVO: 0.80, attribute: 0.85, prepositional: 0.75). Relations are only added to the graph if both subject and object entities exist, ensuring graph consistency.
The knowledge graph is implemented as a NetworkX MultiDiGraph, storing entities as nodes (with metadata: displayname, label, confidence, source, mentions) and relations as edges (with metadata: predicate, confidence, pattern, chunkidx).
Graph-Based Retrieval
When a query arrives, the knowledge graph retriever uses a four-strategy cascade for entity linking:
- Exact Match: Normalize query entity and check against normalized graph entities
- Alias Match: Check common aliases (acronyms, variants without suffixes)
- Fuzzy String Match: Use RapidFuzz for approximate string matching (threshold: 0.7)
- Semantic Match: Use sentence-transformers for semantic similarity (threshold: 0.7)
Once entities are linked, the retriever performs breadth-first traversal to discover related entities:
# Simplified knowledge graph retrieval
def kg_retrieve(query: str, graph: MultiDiGraph, max_hops: int = 2):
# 1. Entity linking (4-strategy cascade)
query_entities = extract_entities(query) # NER on query
matched_entities = []
for entity in query_entities:
matches = link_entity(entity, graph) # Returns up to 3 matches
matched_entities.extend(matches)
# 2. Multi-hop traversal with confidence decay
chunk_scores = {}
for entity, similarity in matched_entities:
# Direct match (hop 0): full similarity score
chunks = graph.nodes[entity].get("chunks", [])
for chunk_id in chunks:
chunk_scores[chunk_id] = chunk_scores.get(chunk_id, 0) + similarity
# Traverse neighbors (hops 1-2)
for hop in range(1, max_hops + 1):
neighbors = list(graph.neighbors(entity))
decay_factor = 0.7 ** hop # Confidence decay
for neighbor in neighbors:
neighbor_chunks = graph.nodes[neighbor].get("chunks", [])
neighbor_similarity = similarity * decay_factor
for chunk_id in neighbor_chunks:
chunk_scores[chunk_id] = (
chunk_scores.get(chunk_id, 0) + neighbor_similarity
)
entity = neighbor # Continue traversal
# 3. Return top-k chunks by score
sorted_chunks = sorted(chunk_scores.items(), key=lambda x: x[1], reverse=True)
return [chunk_id for chunk_id, score in sorted_chunks[:top_k]]
The confidence decay formula (decay_factor = 0.7^hops) ensures direct matches get full weight, one-hop neighbors get 70% weight, and two-hop neighbors get 49% weight. This balances precision (preferring direct matches) with recall (allowing multi-hop exploration).
Integration with Hybrid Retrieval
The knowledge graph retriever integrates with BM25 and dense vector retrieval via Reciprocal Rank Fusion, using default weights [0.4, 0.4, 0.2] for [BM25, Dense, KG]. The KG retriever is optional and gracefully degrades: if construction fails or no entities are matched, the system falls back to BM25 + Dense only, ensuring the system remains functional even when knowledge graph features are unavailable.
The domain-agnostic design makes knowledge graph features practical for RAG systems without requiring domain-specific schemas or expensive LLM-based extraction. By leveraging universal linguistic patterns and confidence-based scoring, the system achieves a balance between extraction quality, performance, and cost.
Comparison with LightRAG and GraphRAG
Our approach differs from other prominent knowledge graph-enhanced RAG systems in several key ways:
LightRAG uses LLMs for entity and relationship extraction, constructing knowledge graphs by analyzing document chunks with language models to identify entities and their interconnections. LightRAG employs a dual-level retrieval paradigm (low-level for specific information, high-level for broader concepts) and supports incremental updates to the knowledge graph. While LLM-based extraction can handle implicit relations and complex patterns, it comes with significant computational cost—every document chunk requires LLM inference, which can be expensive for large corpora.
GraphRAG (Microsoft) integrates knowledge graphs with LLMs as a reasoning engine, focusing on leveraging structured knowledge graphs for efficient querying and retrieval. GraphRAG’s approach often assumes pre-existing knowledge graphs or uses LLM-based construction methods similar to LightRAG. The system emphasizes using the structured nature of knowledge graphs for targeted information retrieval and complex query processing.
Our Approach differs in three fundamental ways:
Rule-Based Extraction vs. LLM-Based: Our system uses rule-based NLP (spaCy NER + linguistic patterns) instead of LLMs for entity and relation extraction. This provides:
- Cost efficiency: No LLM calls during graph construction (~1000 documents/minute vs. seconds per document with LLMs)
- Deterministic extraction: Consistent results across runs, easier to debug and validate
- No API dependencies: Works entirely offline without external LLM services
Domain-Agnostic Patterns: Unlike systems that may require domain-specific schemas or LLM prompts, our universal linguistic patterns (SVO, copula, attribute, prepositional) work across domains without configuration. This makes the system immediately applicable to new domains without fine-tuning.
Hybrid Integration: Our knowledge graph integrates as one component of a three-way hybrid retrieval system (BM25 + Dense + KG), with configurable weights allowing different balance points. LightRAG uses a dual-level paradigm that operates on graph structure itself, while GraphRAG focuses primarily on graph-based retrieval.
Trade-offs
The rule-based approach has clear advantages in cost and performance, but comes with trade-offs:
Advantages:
- Fast, low-cost graph construction (no LLM inference)
- Deterministic, reproducible extraction
- Works offline without external services
- Domain-agnostic without configuration
Limitations:
- Limited to explicit linguistic patterns (misses implicit relations)
- English-only (spaCy dependency)
- Less flexible than LLM-based extraction for complex patterns
LLM-based approaches (LightRAG, GraphRAG) offer:
- Advantages: Can capture implicit relations, handle complex patterns, potentially better quality
- Limitations: Higher cost, slower construction, requires LLM services, potential non-determinism
For RAG systems where cost, speed, and reliability are critical, our rule-based approach provides a practical middle ground—good enough extraction quality with reasonable performance characteristics. The system gracefully degrades when knowledge graph features are unavailable, ensuring reliability even when graph construction fails.
Cross-Encoder Reranking
After retrieval, the system can rerank results using a cross-encoder model, which provides better precision than bi-encoder models (used for initial retrieval) but is too slow to run on the entire corpus:
def rerank(query: str, documents: list[Document], top_k: int = 10):
# Cross-encoder is slow, so we only rerank top-k retrieved documents
scores = cross_encoder.predict([(query, doc.content) for doc in documents])
# Sort by score and return top-k
reranked = sorted(
zip(documents, scores),
key=lambda x: x[1],
reverse=True
)[:top_k]
return [doc for doc, score in reranked]
Reranking improves precision by re-scoring the top retrieved documents with a more powerful model, but adds latency. The system supports disabling reranking for faster responses.
Citation Tracking and Validation
The system maintains full citation tracking throughout the workflow, ensuring all factual claims are attributed to source documents.
Evidence Store
The evidence store tracks all retrieved documents with citation metadata:
@dataclass
class EvidenceChunk:
evidence_id: str # Stable ID (chunk_id)
source_id: str # Document ID
chunk_id: str # Chunk ID
uri: str # Source path or URL
title: str | None
chunk_text: str
page_start: int | None # For PDFs
page_end: int | None
section_title: str | None
The evidence store is maintained in state (evidence_by_id, evidence_sets, used_citations) and is used to validate citations in the final answer.
Citation Format
The system uses [Source N] format for citations, where N corresponds to the source number in the retrieved context. Citations are validated against the evidence store to prevent hallucination.
Citation Validation
After answer generation, the system validates citations to ensure they reference actual retrieved documents:
def _validate_citations(answer: str, context: str) -> tuple[str, bool]:
# Extract citations from answer
answer_citations = _extract_citation_ids(answer) # Finds [Source N] patterns
# Extract source numbers from context
context_sources = set(re.findall(r"Source\s+(\d+)", context, re.IGNORECASE))
valid_sources = {f"Source {s}" for s in context_sources}
# Find invalid citations
invalid_citations = answer_citations - valid_sources
if invalid_citations:
# Remove invalid citations from answer
cleaned_answer = answer
for invalid in invalid_citations:
pattern = rf"\[{re.escape(invalid)}\]"
cleaned_answer = re.sub(pattern, "", cleaned_answer, flags=re.IGNORECASE)
return cleaned_answer, False
return answer, True
This validation prevents hallucinated citations and ensures all citations reference actual retrieved documents.
Structure-Aware Chunking
The system uses structure-aware chunking that preserves document structure (headings, sections, code blocks) and maintains consistent citation metadata across document types (PDFs, Markdown, HTML). This improves citation quality and makes it easier to trace claims back to source documents.
Evaluation Framework
The system includes a comprehensive evaluation framework using the MIRAGE benchmark and RAGAS metrics to measure performance on complex queries.
MIRAGE Dataset
MIRAGE (Metric-Intensive Retrieval-Augmented Generation Evaluation) is a benchmark comprising 7,560 curated QA instances and a 37,800-document retrieval pool. It includes:
- Multi-hop queries requiring information from multiple sources
- Compare/contrast questions
- Evaluation questions
- Questions with explicit constraints
Note that we use a small subset, usually just 30 sanmples, of MIRAGE dataset for faster validation and experimentation, but in order to test the efficacy of finding the correct context and evaluating metrics for things like context recall and precision there are a number of additional context entries selected (500 usually) so that the dataset is not just the 30 samples we are checking for correct answer for.
This is NOT the most meaningfully experiment statistically, but it does allow some basic validation on what makes things better, worse, or roughly the same while experimenting cheaply and only waiting a few to then minutes for each run.
The benchmark provides a realistic test of RAG system capabilities beyond simple Q&A.
RAGAS Metrics
The system uses RAGAS (Retrieval-Augmented Generation Assessment) metrics for evaluation:
- Faithfulness: Measures whether the answer is grounded in the retrieved context (anti-hallucination)
- Answer Relevancy: Measures how relevant the answer is to the question
- Context Precision: Measures the precision of retrieved context (how many retrieved chunks are relevant)
- Context Recall: Measures the recall of retrieved context (how much relevant information was retrieved)
These metrics are calculated using LLM-as-a-judge evaluation, providing automated assessment without requiring ground truth labels.
Workflow Metrics
The system also tracks workflow-specific metrics:
- Retrieval decision accuracy: How often the system correctly decides to retrieve vs. respond directly
- Query rewriting effectiveness: How often query rewriting improves retrieval
- Multi-hop metrics: Reasoning score, document chain quality, information integration
These metrics help understand system behavior beyond answer quality.
Retrieval Method Ablation Study
An ablation study compared individual retrieval methods (KG-only, Dense-only, BM25-only) against the hybrid baseline that combines all three methods with weights [0.4, 0.4, 0.2] for [BM25, Dense, KG]. The evaluation used the MIRAGE benchmark with 30 examples and a 500-document noise pool, providing insights into how each retrieval method contributes to overall system performance.
Individual Method Performance
The study revealed that no single retrieval method dominates across all metrics:
KG-only: Achieved the best context precision (+7.8%) and context recall (+7.2%) among individual methods, demonstrating that graph-based entity relationships help find relevant documents. However, it showed lower faithfulness (-5.8%) compared to hybrid, suggesting KG-retrieved documents may contain more diverse but less consistent information.
Dense-only: Showed good context recall (+7.1%) and maintained answer relevancy similar to hybrid, but had the lowest faithfulness (-10.9%) among all methods. This indicates that semantic similarity alone can introduce inconsistencies despite finding relevant documents.
BM25-only: Maintained faithfulness equivalent to hybrid (0.9925 vs. 0.9924), demonstrating that keyword matching provides the most reliable grounding. However, it showed the lowest answer relevancy (-9.9%), suggesting keyword matching alone may miss semantic nuances important for answer quality. BM25-only was also the fastest, evaluating 47.5% faster than hybrid.
Hybrid Configuration Results
The hybrid configuration (weights [0.4, 0.4, 0.2]) achieved the highest faithfulness (0.9924) by balancing the strengths of all three methods. No single method could match this performance, confirming that hybrid retrieval provides optimal faithfulness through complementary contributions.
Weight Optimization
Subsequent weight optimization studies found that increasing KG weight to 0.4 (with BM25 and Dense reduced to 0.3 each, configuration [0.3, 0.3, 0.4]) achieved even better performance:
- Perfect faithfulness (1.0000): Eliminated hallucinations entirely
- Best context recall (+2.32%): Improved document coverage
- Best answer relevancy (+1.00%): More relevant answers
- 60% faster evaluation time: Significant performance improvement
This suggests that the KG-heavy configuration [0.3, 0.3, 0.4] may be optimal for balancing faithfulness, recall, and performance.
Key Insights
The ablation study demonstrates several important principles for real life RAG systems:
Complementary Strengths: Each retrieval method (BM25, Dense, KG) contributes unique capabilities—BM25 excels at keyword recall and faithfulness, Dense excels at semantic recall, and KG excels at precision and entity-based retrieval.
Faithfulness Trade-offs: Keyword matching (BM25) provides the most faithful retrieval, while semantic and graph-based methods trade some faithfulness for better recall. The hybrid approach balances these trade-offs.
Weight Configuration Matters: The optimal weight configuration depends on the desired balance between faithfulness, recall, and performance. The KG-heavy configuration [0.3, 0.3, 0.4] appears optimal for most use cases.
Performance Considerations: BM25 is significantly faster than KG or hybrid retrieval, making it preferable when speed is critical. However, hybrid retrieval provides better overall quality at the cost of additional computation.
Key Findings
Results
┌────────────────┬───────────────────┬────────────────┬──────────────┬──────────────────┐
│ Configuration │ Context Precision │ Context Recall │ Faithfulness │ Answer Relevancy │
├────────────────┼───────────────────┼────────────────┼──────────────┼──────────────────┤
│ Naive RAG │ 0.64 │ 0.96 │ 0.95 │ 0.90 │
├────────────────┼───────────────────┼────────────────┼──────────────┼──────────────────┤
│ RAG Agent │ 0.68 (+5.4%) │ 0.89 (-7.0%) │ 0.93 │ 0.89 │
├────────────────┼───────────────────┼────────────────┼──────────────┼──────────────────┤
│ RAG Agent + KG │ 0.69 (+8.2%) │ 0.91 (-5.1%) │ 0.94 │ 0.90 │
└────────────────┴───────────────────┴────────────────┴──────────────┴──────────────────┘
- Context Precision Improvement: KG shows +8.2% improvement over naive RAG (0.64 → 0.69)
- Context Recall Trade-off: The agentic workflow trades off some recall for better precision
- Faithfulness: All configurations maintain high faithfulness (0.93-0.95)
Answer Relevancy: Stable across all configurations (~0.90)
Evaluation results on MIRAGE (100 examples) show precision improvements with the agentic approach:
- Context precision: 0.64 (naive) → 0.69 (with KG, +8.2% improvement)
- Context recall: 0.96 (naive baseline maintained high recall)
- Faithfulness: 0.94 (strong grounding in context)
- Answer relevancy: 0.90 (relevant answers)
Using the System
The system provides both a CLI and Python API for different use cases.
CLI Usage
Index documents and query using the command-line interface:
# Index documents from a URL
rag-agent index https://example.com/docs --store-path ./my_store
# Query interactively
rag-agent query --store-path ./my_store --interactive
# Single query
rag-agent query "What is RAG?" --store-path ./my_store --show-sources
# Use specific model
rag-agent query "Explain agents" --store-path ./my_store \
--provider openai --model gpt-4o
The CLI supports interactive mode with conversation history, citation display, and verbose output for debugging.
Python API
Create agents programmatically:
from rag_agent import create_rag_agent
# Create agent from URLs
agent = create_rag_agent(
urls=["https://example.com/doc1", "https://example.com/doc2"],
model_name="gpt-4o"
)
# Query the agent
response = agent.query("What is the return policy?")
print(response)
All advanced features are enabled by default (query decomposition, HyDE, hybrid retrieval, reranking). You can disable features for faster responses:
agent = create_rag_agent(
urls=["https://example.com/docs"],
model_name="gpt-4o",
enable_query_decomposition=False, # Disable map-reduce
enable_hyde=False, # Disable query expansion
enable_hybrid_retrieval=False, # Use dense retrieval only
)
Production Considerations
For production use, use persistent vector stores (LanceDB) instead of in-memory stores. The system supports reuse of existing stores for faster startup:
# First run: create and index
agent1 = create_rag_agent(
documents=documents,
model_name="gpt-4o",
vectorstore_type="lancedb",
vectorstore_path="./prod_vectorstore",
mode="overwrite"
)
# Subsequent runs: reuse existing store
agent2 = create_rag_agent(
documents=[], # Empty - will reuse existing
model_name="gpt-4o",
vectorstore_type="lancedb",
vectorstore_path="./prod_vectorstore",
reuse_existing=True
)
The system also supports conversation history management for multi-turn interactions, metadata filtering for source-specific retrieval, and MMR (Maximal Marginal Relevance) for result diversity.
Challenges and Trade-offs
Building real-world production-grade agentic RAG systems involves several trade-offs:
Citation Strictness
Requiring citations for all factual claims improves faithfulness (reduces hallucination) but can reduce answer relevancy if the system is overly conservative. The system balances this by allowing answers to proceed even if some claims lack citations, but flagging them in the output.
Latency vs. Quality
More LLM calls improve quality (through iterative refinement and query decomposition) but increase latency and cost. The system allows disabling advanced features for faster responses, but this reduces quality on complex queries.
On complex queries, the system typically requires:
- 3-6 LLM calls (for query decomposition)
- 2-4 retrieval passes (for iterative refinement)
- Multiple synthesis steps
This can result in 5-10 second response times, which may be acceptable for research assistants but not for real-time chatbots.
Complexity vs. Usability
Advanced features (query decomposition, HyDE, hybrid retrieval) require configuration and understanding of their effects. The system makes these features opt-in (though enabled by default), allowing users to simplify the system if needed.
The modular architecture helps here: each feature can be enabled or disabled independently, and the graph structure adapts accordingly.
Performance Overhead
Knowledge graph features (optional) add significant latency during graph construction and traversal. The system disables knowledge graph by default, using it only when explicitly enabled.
Even without knowledge graphs, the system has overhead from:
- Multiple LLM calls
- Structured output parsing
- State management
- Citation validation
These overheads are necessary for the improved quality but may be prohibitive for simple use cases where naive RAG would suffice.
Conclusion
Building adaptable agentic RAG systems requires moving beyond the naive retrieve-then-generate pattern. By introducing intelligent decision-making, iterative refinement, and query decomposition, we can achieve significant improvements in context precision and recall.
The key insights are:
- Agents enable adaptive workflows that adjust to query complexity, avoiding the one-size-fits-all approach of naive RAG
- Evidence-gap analysis allows iterative improvement without guessing, enabling targeted query rewriting based on missing information
- Map-reduce decomposition solves the multi-hop problem elegantly, achieving near-perfect context precision while maintaining high recall
- Modular architecture makes systems adaptable to different use cases, from simple Q&A to complex research assistants
- Evaluation-driven development ensures improvements are real, not perceived—the MIRAGE benchmark reveals where naive RAG fails and agentic approaches succeed
The rag_agent project demonstrates that building real RAG systems requires significant infrastructure beyond the core retrieval and generation logic: state management, routing, instrumentation, evaluation, and testing. When you compare the size of the agent code to the supporting infrastructure, it becomes clear where the real work lies in a practical production-ready solution.
The system is open-source and available at https://github.com/ranton256/rag_agent, with tests, documentation, and evaluation code all included. Future enhancements may include multi-query expansion, deeper integration with knowledge graphs, and improved evaluation metrics, but the current system provides a solid foundation for building agentic RAG applications.
References
Anton, R. (2024, April 22). LangChain and Streamlit RAG. Medium. https://medium.com/snowflake/langchain-and-streamlit-rag-c5f53af8f6ba
Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023). RAGAS: Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations (pp. 222–231). Association for Computational Linguistics. https://doi.org/10.48550/arXiv.2309.15217
Gao, L., Ma, X., Lin, J., & Callan, J. (2023). Precise zero-shot dense retrieval without relevance labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1762–1777). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-long.99
Goldstein, J., & Carbonell, J. (1998). Summarization: (1) Using MMR for diversity-based reranking and (2) Evaluating summaries. In TIPSTER TEXT PROGRAM PHASE III: Proceedings of a Workshop (pp. 181–195). Association for Computational Linguistics.
Guo, Z., Xia, L., Yu, Y., Ao, T., & Huang, C. (2024). LightRAG: Simple and fast retrieval-augmented generation. arXiv preprint arXiv:2410.05779. https://arxiv.org/abs/2410.05779
Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and effective passage search via contextualized late interaction over BERT. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 2025–2028). Association for Computing Machinery. https://doi.org/10.1145/3397271.3401075
Krishna, S., Krishna, K., Mohananey, A., Schwarcz, S., Stambler, A., Upadhyay, S., & Faruqui, M. (2025). Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics. https://doi.org/10.48550/arXiv.2409.12941
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020) (pp. 9457–9474). https://doi.org/10.48550/arXiv.2005.11401
Nogueira, R., Jiang, Z., & Lin, J. (2020). Document ranking with a pretrained sequence-to-sequence model. arXiv preprint arXiv:2003.06713. https://arxiv.org/abs/2003.06713
Park, C., Moon, H., Park, C., & Lim, H. (2025). MIRAGE: A metric-intensive benchmark for retrieval-augmented generation evaluation. In Findings of the Association for Computational Linguistics: NAACL 2025 (pp. 2883–2900). Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.findings-naacl.157
Rackauckas, Z. (2024). RAG-Fusion: A new take on retrieval-augmented generation. International Journal on Natural Language Computing, 13(1), 37–44. https://doi.org/10.5121/ijnlc.2024.13103